Da du mir augenscheinlich einfach nicht glauben willst, argumentiere ich jetzt einfach mal auf Basis des Buches "Tontechnik" meines ehemaligen Nachrichtentechnik-Professors Thomas Görne

1. Ich will mich jetzt natürlich nicht um Formulierungen streiten.
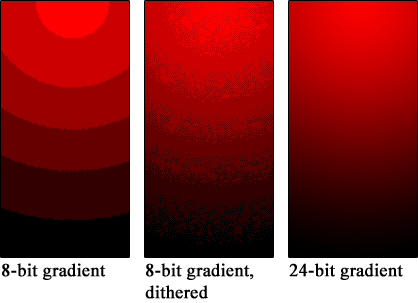
2. "Wird ein extrem rauscharm aufgenommenes Signal leise (zum Beispiel Ausklang eines Tons in sehr stiller Umgebung), dann bekommen die Quantisierungsfehler den Charakter einer nichtlinearen Verzerrung, extrem kleine Signale werden als Rechteck wiedergegeben, und aus dem harmlosen Quantisierungsrauschen wird das unangenehme granulare Rauschen.(...) Abhilfe schafft ein additives Rauschsignal vor der Quantisierung (Dither)." (Görne, Thomas: Tontechnik, Seite 161)
3. Da sind wir uns ja einig.
4. Hierzu gibt es leider kein so knackiges Zitat, deswegen erlaube ich mir mal das in eigene Worte zu fassen:
Noise Shaping ist ein Verfahren zur verminderung des Quantisierungsrauschens. Hierbei arbeitet man erst mal mit einer höheren Auflösung, als der Quantisierer eigentlich vorsieht. Dann wird die Wortbreite reduziert und der dadurch entstehende Quantisierungsfehler wird an den Eingang rückgekoppelt. Bei Gleichspannung führt das zu einer starken Verminderung des Quantisierungsrauschens. Je höher die Frequenz wird, desto unwirksamer wird das Verfahren jedoch und schließlich wird das Rauschen sogar erhöht. Es entsteht also nicht etwa rosa Rauschen, sondern das Rauschen nimmt mit der Frequenz zu! Die Idee dahinter ist, dass das Hörvermögen des Menschen bei hohen Frequenzen abnimmt. Wirklich wirksam ist das Verfahren aber erst, wenn man es mit Oversampling kombiniert und das Rauschen in den nicht mehr wahrnehmbaren Bereich verschoben wird.
(siehe Görne, Thomas: Tontechnik, Seite 166-167)
Ich weiß, teilweise wurde das schon gesagt, allerdings hat das definitiv nichts mit Filtern, rosa Rauschen oder sowas zu tun. Da wurde wohl einiges an Halbwissen vermischt...
5. Wenn man rosa Rauschen auf weißes Rauschen addiert, erhält man aber kein rosa Rauschen. Außerdem ist Dither schlicht und einfach kein rosa Rauschen:
"Je nach Amplitudenverteilung unterscheidet man u.a. Dither mit rechteckiger, dreieckiger und Gauß'scher Verteilung.(...) Ideal für rein digitale Dither-Implementierungen ist die Dreieck-Verteilung. (...) Günstig für Analog-Digital-Wandler ist die Gauß-Verteilung (Normalverteilung) der Ampltude, wie sie bei natürlichem thermischen Rauschen auftritt." (Görne, Thomas: Tontechnik, Seite 166)
Mehrfaches Dithern:
"Analog-Digital-Wandler sind grundsätzlich gedithert. Darüber hinaus kann Dither optional eingesetzt werden wenn das Signal...
- re-quantisiert wird, wenn also z.B. die Wortbreite von 24 auf 16 Bit reduziert wird (Verringerung von Quantisierungsrauschen);
- mit einem rationalen Faktor multipliziert wird, wenn also z.B. das Signal mit digitalen Filtern bearbeitet wird (Verringerung von Rundungsrauschen);
- in der Amplitude verändert wird, wenn also z.B. das Signal ein-oder ausgeblendet wird."
(Görne, Thomas: Tontechnik, Seite 165)
Punkt zwei und Drei sind ja beim Mix eigentlich immer erfüllt, sprich: Nach dem Mix ist Dithern sinnvoll!
Hierbei wundert mich jetzt alleding, dass Dithern wohl tatsächlich eingesetzt wird um Quantisierungsrauschen zu verringern. Kann ich mir selbst nicht erklären. Ich hoffe da kann mich jemand belehren

Ich hoffe die Mühe war es Wert...






 Ich schätze, dass 24bit für Pop/Rockproduktionen völlig ausreichend sind. Wie es zum Beispiel bei der Aufnahme klassischer Konzerte aussieht, kann ich nicht beurteilen.
Ich schätze, dass 24bit für Pop/Rockproduktionen völlig ausreichend sind. Wie es zum Beispiel bei der Aufnahme klassischer Konzerte aussieht, kann ich nicht beurteilen.