B
broeschies
Registrierter Benutzer
- Zuletzt hier
- 21.10.19
- Registriert
- 29.01.12
- Beiträge
- 2.154
- Kekse
- 3.180
Für diejenigen, die ein bisschen physiologisch interessiert sind und sich schon immer gefragt haben, was diese Register überhaupt sind, hier eine interessante Studie. Das interessante an dieser Studie ist, dass es Soundbeispiele gibt (!), was bei den meisten Studien selten der Fall ist. Die Studie gibt in diesem Artikel erstmal einen kleinen Einblick, wie man die Register im EGG-Signal erkennt, und wie man die "Masse" der Stimmlippen erkennt.
http://voce-faringea.com/en/paramet...registers-modal-falsetto-and-voce-faringea-2/
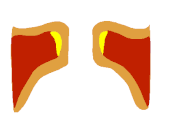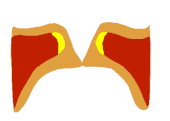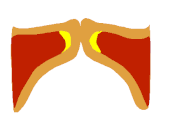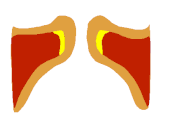
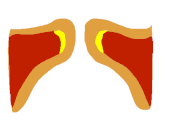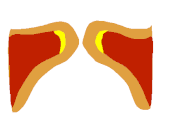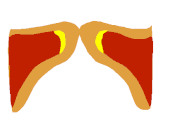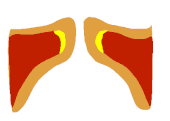
Auf Seite 15 die Bilder 17-22 zeigen wie sich die Form des EGG-Signals nahezu 1:1 auf den Zustand der Stimmlippen übertragen lässt. Man sieht schön den Unterschied zwischen Vollstimme (links) und Falsett (mitte). Interessant ist aber die Koordination, die hier "voce faringea" genannt wird. Das entspricht dem, was viele unter "mixed voice", "Fake-Belt", was auch immer verstehen, also eine Koordination, die nicht so richtig Bruststimme ist, aber auch nicht so richtig Falsett.
Die Studie zeigt, dass die "Masse" in dieser Koordination ähnlich groß ist wie in der Vollstimme (aber schon ein bisschen kleiner). Fast noch interessanter ist aber, dass der sub-glottische Druck in dieser Koordination sogar noch geringer (!) ist als im Falsett.
Ähnlich interessant sind diese Beispiele aus der selben Studie
http://voce-faringea.com/en/audio-samples-and-analysis/
Oben der Unterschied zwischen "voce faringea" und "Falsett", ganz unten zwischen "brustdominantem Mix" (Vollstimme) und "voce faringea". Hier sieht man einen deutlichen Unterschied zwischen voce faringea und Falsett, aber eben auch nochmal einen sichtbaren Unterschied zwischen voce faringea und Vollstimme. Und auch hier ist die Masse in der voce faringea deutlich sichtbar größer als im Falsett, aber kleiner als in der Vollstimme.
Schließlich könnt ihr euch noch die Soundbeispiele anhören, und mal ehrlich, wer hätte die unterschiedlichen Schwingungsregister erkannt? Im binären System (Vollstimme/Randstimme) ist die voce faringea eher als Vollstimme zu sehen, weil die EGG-Signale andeuten, dass der Vocalis-Muskel noch mitschwingt, nur eben nicht über seiner vollen Tiefe. Gerade im letzten Beispiel hätte ich persönlich die erste Koordination aber z.B. als randstimmig eingeordnet.
TLDR: Es verdichten sich die Zeichen, dass das System Vollstimme/Randstimme nicht so binär ist wie lange Zeit geglaubt wurde (und dass zudem die klanglichen Unterschiede marginal sein können).
http://voce-faringea.com/en/paramet...registers-modal-falsetto-and-voce-faringea-2/
Auf Seite 15 die Bilder 17-22 zeigen wie sich die Form des EGG-Signals nahezu 1:1 auf den Zustand der Stimmlippen übertragen lässt. Man sieht schön den Unterschied zwischen Vollstimme (links) und Falsett (mitte). Interessant ist aber die Koordination, die hier "voce faringea" genannt wird. Das entspricht dem, was viele unter "mixed voice", "Fake-Belt", was auch immer verstehen, also eine Koordination, die nicht so richtig Bruststimme ist, aber auch nicht so richtig Falsett.
Die Studie zeigt, dass die "Masse" in dieser Koordination ähnlich groß ist wie in der Vollstimme (aber schon ein bisschen kleiner). Fast noch interessanter ist aber, dass der sub-glottische Druck in dieser Koordination sogar noch geringer (!) ist als im Falsett.
Ähnlich interessant sind diese Beispiele aus der selben Studie
http://voce-faringea.com/en/audio-samples-and-analysis/
Oben der Unterschied zwischen "voce faringea" und "Falsett", ganz unten zwischen "brustdominantem Mix" (Vollstimme) und "voce faringea". Hier sieht man einen deutlichen Unterschied zwischen voce faringea und Falsett, aber eben auch nochmal einen sichtbaren Unterschied zwischen voce faringea und Vollstimme. Und auch hier ist die Masse in der voce faringea deutlich sichtbar größer als im Falsett, aber kleiner als in der Vollstimme.
Schließlich könnt ihr euch noch die Soundbeispiele anhören, und mal ehrlich, wer hätte die unterschiedlichen Schwingungsregister erkannt? Im binären System (Vollstimme/Randstimme) ist die voce faringea eher als Vollstimme zu sehen, weil die EGG-Signale andeuten, dass der Vocalis-Muskel noch mitschwingt, nur eben nicht über seiner vollen Tiefe. Gerade im letzten Beispiel hätte ich persönlich die erste Koordination aber z.B. als randstimmig eingeordnet.
TLDR: Es verdichten sich die Zeichen, dass das System Vollstimme/Randstimme nicht so binär ist wie lange Zeit geglaubt wurde (und dass zudem die klanglichen Unterschiede marginal sein können).
- Eigenschaft


")