makle
Registrierter Benutzer
Hallo Forengemeinde,
der Sachverhalt richtet sich an alle Open Office Experten hier im Forum.
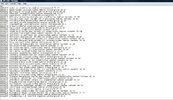
Ich habe mehrere PDFs mit jeweils ca. 20 Seiten mit vollständigen Tabellen.
In diesen Tabellen habe ich Text und Zahlen, die ich in mein Scal. Programm übernehmen und dort auswerten möchte.
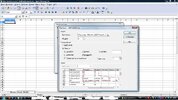
Nun habe ich es schon geschafft die PDF als Text zu speichern und über die Funktion "Tabelle einfügen" mittels Spaltentrennung einzelne Abtrennungen vorzunehmen. Leider schaffe ich es nicht einfach den Text in eine Spalte und die Zahlen in vereinzelte Spalten danach einzuteilen.
Weiß dort jemand eine Lösung? als Beispiel habe ich ein paar Bilder angehangen.
Ich freue mich auf eure Antworten")
der Sachverhalt richtet sich an alle Open Office Experten hier im Forum.
Ich habe mehrere PDFs mit jeweils ca. 20 Seiten mit vollständigen Tabellen.
In diesen Tabellen habe ich Text und Zahlen, die ich in mein Scal. Programm übernehmen und dort auswerten möchte.
Nun habe ich es schon geschafft die PDF als Text zu speichern und über die Funktion "Tabelle einfügen" mittels Spaltentrennung einzelne Abtrennungen vorzunehmen. Leider schaffe ich es nicht einfach den Text in eine Spalte und die Zahlen in vereinzelte Spalten danach einzuteilen.
Weiß dort jemand eine Lösung? als Beispiel habe ich ein paar Bilder angehangen.
Ich freue mich auf eure Antworten
- Eigenschaft